Chris Callison-Burch: Teaching Statement
(Last updated November 2023)
I teach one of the most popular classes at Penn, which is our Artificial Intelligence (AI) course. This semester (Fall 2023), the course has an enrollment of 600 students – 400 in-person, plus 200 online students who are doing a master’s from Penn Engineering Online. Even with more than 500 students in my course, I consistently receive excellent teaching reviews. I worked hard to achieve this scale and quality in my teaching.
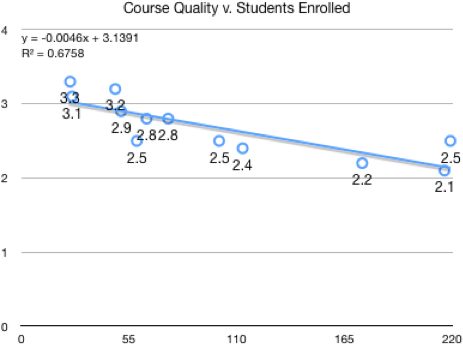
Figure 1: As course size grows, student reviews tend to go down.
Back in 2018, I plotted my teaching reviews against my course sizes and found an anti-correlation (Figure 1). I set myself the goal of flattening the trend so that I could continue to offer large courses and have the students’ experience be as positive as when I offer smaller, more personal courses. I undertook a variety of improvements:
- I improved the organization of my courses
- I developed better course materials, including high-quality recorded videos and good, auto-graded assignments
- I designed a fun set of hands-on extra credit assignments that use programmable toy R2D2s to demonstrate the key ideas in my AI course.
- I recruited and organized teams of TAs (each year I have 30+ students return as TAs)
- During the pandemic, I developed course policies that were empathetic to students’ learning situation.
I’m proud to say that I managed to eliminate the inverse correlation between class size and course reviews (Figure 2). Since dedicating myself to improving my teaching quality, my reviews have steadily gone up, and my courses are now consistently rated between ‘very good’ and ‘excellent’ (Figure 3).
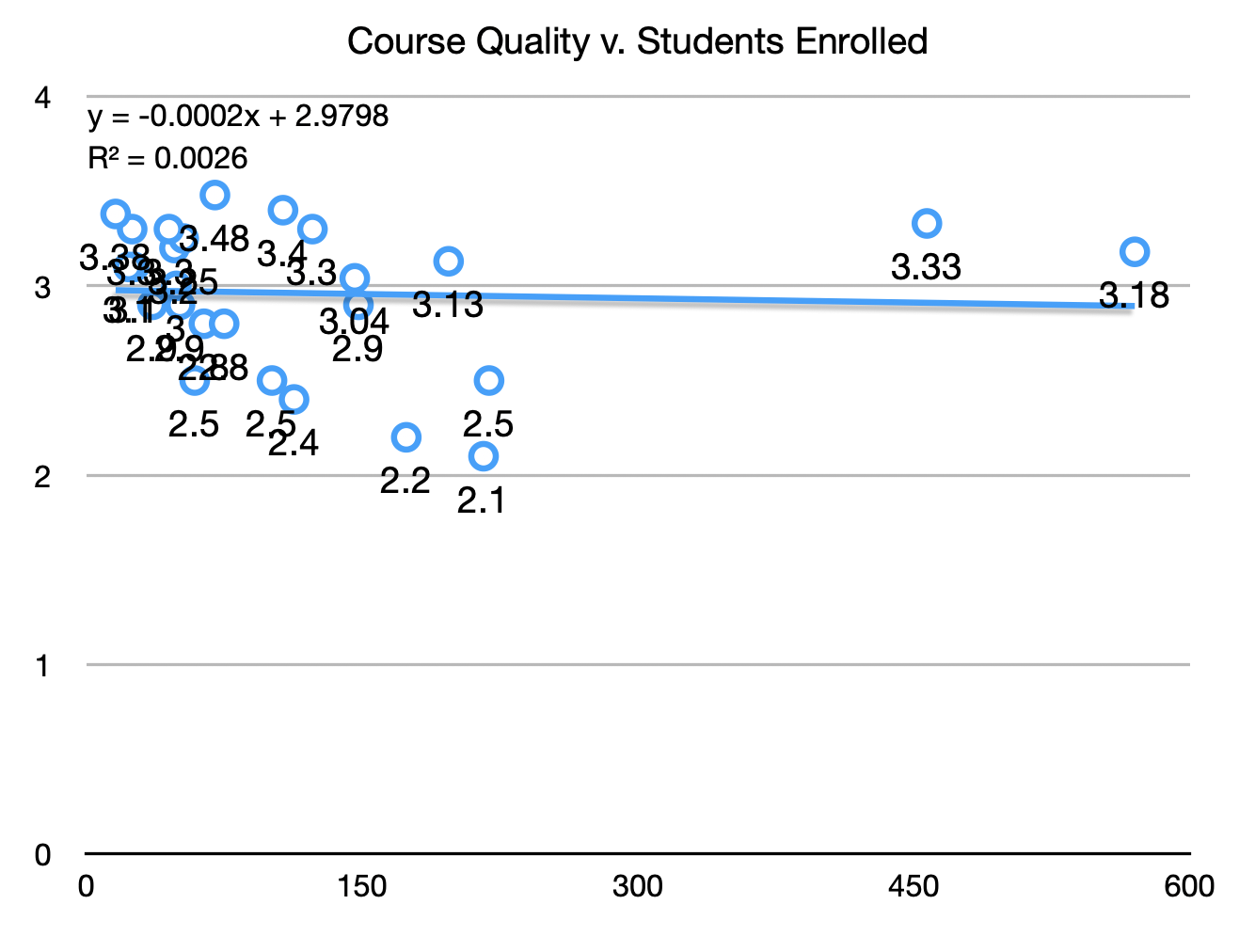
Figure 2: My course reviews are no longer negatively correlated with course size.
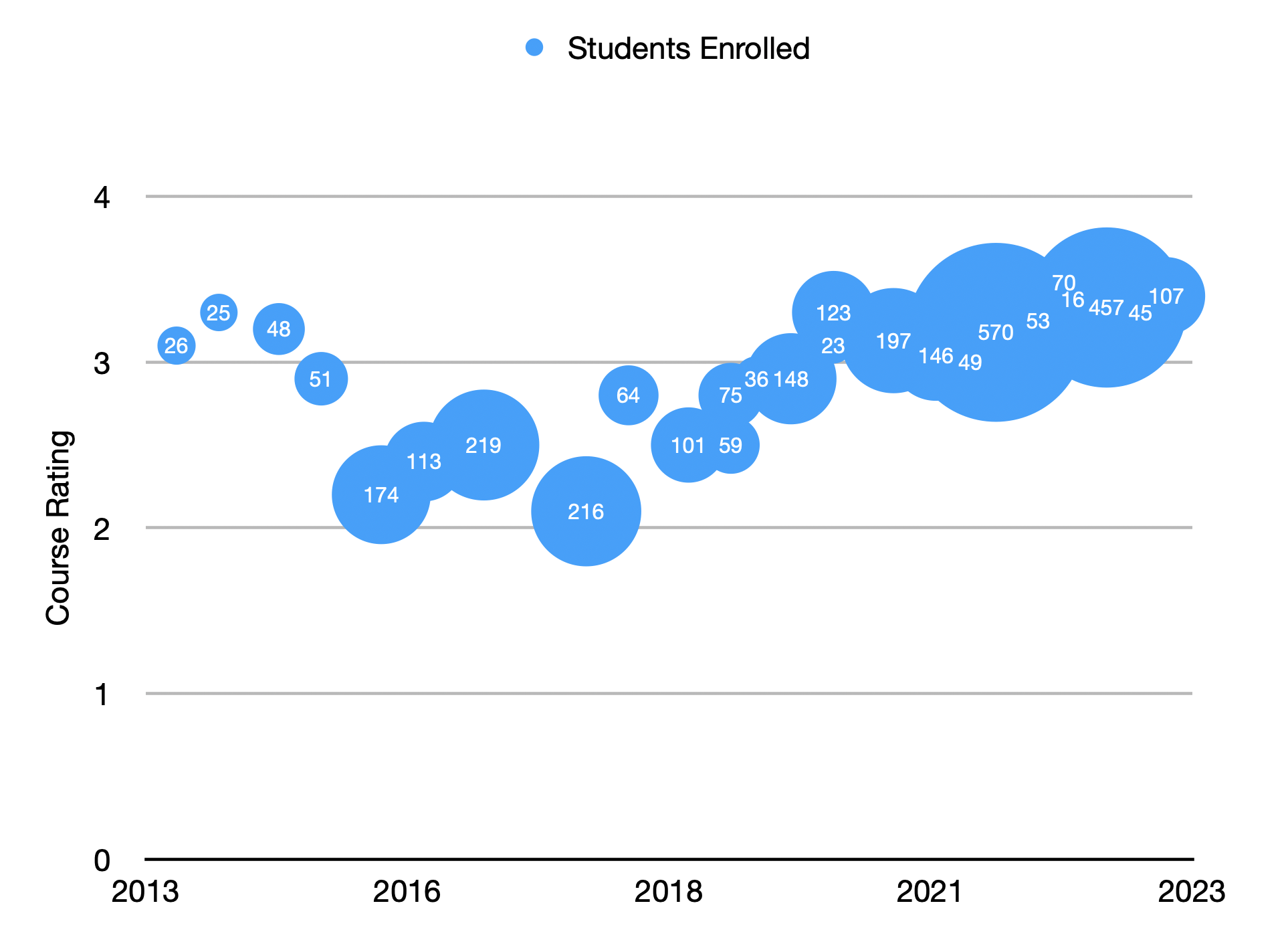
Figure 2: My course reviews have gone up since 2018 when I dedicated myself to improving teaching.
I have designed two courses for Penn Engineering Online: Artificial Intelligence and Natural Language Processing. I re-designed NLP while I was on sabbatical last year to center the course on large language models. My online courses are not “watered down”. The content of the courses is identical to what I teach in my on-campus courses. In fact, my on-campus courses have improved as a result of my investing the effort I put into creating the online courses. I carefully thought out the course design. I recorded high-quality lecture videos. I designed homework assignments that are auto-graded and give students instant feedback.
I frequently take on extra teaching duties for Penn Engineering Online, and voluntary overloads. This semester I’m teaching a total of 750 students. 600 in AI, 150 in NLP, and about 20 enrolled in my PhD seminar on Large Language Models and Programming Languages (which I’m teaching for fun in collaboration with Benjamin Pierce a PL faculty member here at Penn).
I am proud of my teaching record, and the fact that my large classes get consistently excellent reviews from students.
Teaching Reviews
You can read my full teaching reviews here. Below are the summary statistics.
| Colored rows indicate additional teaching beyond normal requirements. | Taught for Penn Engineering Online | Voluntary teaching overload |
| Penn teaching reviews are on a 0-4 quality scale: | 0=Poor | 1=Fair | 2=Good | 3=Very Good | 4=Excellent |
Quality scale (0-4): 0=Poor, 1=Fair, 2=Good, 3=Very Good, 4=Excellent
| Term | Course Title (Number) | Students Enrolled | Course Quality | Instructor Quality |
|---|---|---|---|---|
| Summer 2025 | Artificial Intelligence (CIS 5210 - Penn Engineering Online) | 132 | ||
| Summer 2025 | Natural Language Prorcessing (CIS 5300 - Penn Engineering Online) | 138 | ||
| Spring 2025 | Intro to Artificial Intelligence (CIS 3990) | 57 | ||
| Spring 2025 | Natural Language Prorcessing (CIS 5300 - Penn Engineering Online) | 237 | 3.4 | 3.7 |
| Fall 2024 | Research Practicum (CIS 8000) | 54 | 2.9 | 3.3 |
| Fall 2024 | Artificial Intelligence (CIS 4210/5210 - on campus) | 373 | 3.1 | 3.3 |
| Fall 2024 | Artificial Intelligence (CIS 5210 - Penn Engineering Online) | 159 | 3.3 | 3.5 |
| Summer 2024 | Natural Language Prorcessing (CIS 5300 - Penn Engineering Online) | 131 | 3.5 | 3.7 |
| Summer 2024 | Artificial Intelligence (CIS 5210 - Penn Engineering Online) | 115 | 3.1 | 3.4 |
| Spring 2024 | Interactive Fiction and Text Generation (CIS 7000) | 53 | 3.4 | 3.7 |
| Fall 2023 | Artificial Intelligence (CIS 4210/5210 - on campus) | 373 | 3.1 | 3.4 |
| Fall 2023 | Artificial Intelligence (CIS 5210 - Penn Engineering Online) | 186 | 3.0 | 3.5 |
| Fall 2023 | Natural Language Processing (CIS 5300 - Penn Engineering Online) | 152 | 3.2 | 3.6 |
| Fall 2023 | Large Language Models and Programming Languages (CIS 8000) | 12 | 3.5 | 3.5 |
| Summer 2023 | Artificial Intelligence (CIS 5210 - Penn Engineering Online) | 107 | 3.4 | 3.5 |
| Summer 2023 | Natural Language Processing (CIS 5300 - Penn Engineering Online) | 45 | 3.3 | 3.5 |
| Fall 2022 | Artificial Intelligence (CIS 4210/5210 - on campus) | 363 | 3.3 | 3.5 |
| Fall 2022 | Artificial Intelligence (CIS 5210 - Penn Engineering Online) | 94 | 3.4 | 3.6 |
| Fall 2022 | Research Practicum (CIS 8000) | 16 | 3.5 | 3.6 |
| Summer 2022 | Artificial Intelligence (CIS 521 - Penn Engineering Online) | 70 | 3.5 | 3.7 |
| Spring 2022 | Interactive Fiction and Text Generation (CIS 700-001) | 53 | 3.3 | 3.5 |
| Fall 2021 | Artificial Intelligence (CIS 521 - MCIT Online) | 234 | 3.2 | 3.4 |
| Fall 2021 | Artificial Intelligence (CIS 421/521 - on campus - section 1) | 180 | 3.2 | 3.4 |
| Fall 2021 | Artificial Intelligence (CIS 421/521 - on campus - section 2) | 138 | 3.2 | 3.5 |
| Fall 2021 | Artificial Intelligence (CIS 421/521 - online only section for foreign graduate students unable to return to campus due to the pandemic) | 11 | 2.5 | 2.3 |
| Summer 2021 | Artificial Intelligence (CIS 521 - MCIT Online) | 49 | 3.0 | 3.6 |
| Spring 2021 | Crowdsourcing and Human Computation (NETS 213) | 146 | 3.0 | 3.3 |
| Fall 2020 | Artificial Intelligence (CIS 421/521) | 197 | 3.1 | 3.3 |
| Spring 2020 | Computational Linguistics (CIS 530) | 125 | 3.3 | 3.3 |
| Spring 2020 | Interactive Fiction and Text Generation (CIS 700-008) | 23 | 3.1 | 3.3 |
| Fall 2019 | Artificial Intelligence (CIS 421/521) | 148 | 3.1 | 3.3 |
| Summer 2019 | Artificial Intelligence (CIS 421/521) | 36 | 2.9 | 3.0 |
| Spring 2019 | Computational Linguistics (CIS 530) | 75 | 2.8 | 3.0 |
| Spring 2019 | Crowdsourcing and Human Computation (NETS 213) | 59 | 2.5 | 2.7 |
| Fall 2018 | Artificial Intelligence (CIS 421/521) | 101 | 2.5 | 2.5 |
| Spring 2018 | Computational Linguistics (CIS 530) | 64 | 2.8 | 2.7 |
| Fall 2017 | Data Structures and Algorithms (CIS 121) | 216 | 2.1 | 1.7 |
| Fall 2016 | Data Structures and Algorithms (CIS 121) | 219 | 2.5 | 2.2 |
| Spring 2016 | Crowdsourcing and Human Computation (NETS 213) | 113 | 2.4 | 2.8 |
| Fall 2015 | Data Structures and Algorithms (CIS 121) | 174 | 2.2 | 2.2 |
| Spring 2015 | Machine Translation (CIS 526) | 51 | 2.9 | 3.2 |
| Fall 2014 | Crowdsourcing and Human Computation (NETS 213) | 48 | 3.2 | 3.6 |
| Spring 2014 | Machine Translation (CIS 526) | 25 | 3.3 | 3.5 |
| Fall 2013 | Crowdsourcing and Human Computation (CIS 399) | 26 | 3.1 | 3.5 |
Advising Awards
During the pandemic, I won the Ford Motor Company Award for Faculty Advising twice – once in 2021 and once again in 2022. This award is presented annually by the undergraduate student body in recognition of faculty dedication in helping students realize their educational, career and personal goals. I attribute this award to the care I put into teaching and the empathy that I expressed for students during the pandemic when all of our learning rapidly changed to an online remote format. I made several accommodations to students to help mitigate the negative effects of learning online.
Mentorship of Undergraduates and Master’s Students
I have supervised 15 master’s theses and supervised dozens of independent study projects for undergraduates. I found that student interest in doing these outstripped my capacity to supervise them, so last year I experimented with offering a Research Practicum (CIS 8000 – Fall 2022) that guided students through the process of conducting research. We formed teams and worked through projects, starting with literature reviews all the way through writing and editing conference paper submissions. I’m proud to say that this experimental course resulted in 5 publications – 4 in ACL and 1 in the BEA workshop:
- FIREBALL: A Dataset of Dungeons and Dragons Actual-Play with Structured Game State Information – ACL 2023
- Explanation-based Finetuning Makes Models More Robust to Spurious Cues – ACL 2023
- Human-in-the-Loop Schema Induction – ACL 2023 demos
- CORRPUS: Code-based Structured Prompting for Neurosymbolic Story Understanding – ACL 2023 Findings
- Automatically Generated Summaries of Video Lectures May Enhance Students’ Learning Experience – BEA 2023
Mentorship of PhD Students and Postdocs
I am currently supervising or co-supervising 11 PhD students. In my career so far, I have graduated 9 PhD students and supervised 7 postdocs. All of them have gone on to excellent positions. I am especially proud of my mentorship of women – 5 women who I mentored now hold faculty positions. I value the diversity of my group, and I have mentored several URM and LGBTQ students.
PhDs Graduated:
- Aditya Kashyap, University of Pennsylvania (advisors: Chris Callison-Burch and Mary Regina Boland), "Applying Language Models to Patient Health Records: Acronym Expansion, Long Document Classification and Explainable Predictions", January 2025. Current position: Biomedical NLP Engineer at Selfii.
- Veronica Qing Lyu, University of Pennsylvania (advisors: Chris Callison-Burch and Marianna Apidianaki), "Faithful and Useful Explanations by Large Language Models", August 2024. Current position: Researcher at Databricks.
- Harry Li Zhang, University of Pennsylvania (advisor: Chris Callison-Burch), "Structured Event Reasoning with Large Language Models", May 2024. Current position: Assistant Professor at Drexel University.
- Daphne Ippolito, University of Pennsylvania (advisors: Chris Callison-Burch and Doug Eck), "Understanding the Limitations of Using Large Language Models for Text Generation", September 2022. Current position: Assistant Professor at Carnegie Mellon University.
- Reno Kriz, University of Pennsylvania (advisors: Chris Callison-Burch and Marianna Apidianaki), "Towards a Practically Useful Text Simplification System", June 2021. Current position: Research Scientist at Human Language Technology Center of Excellence.
- Anne Cocos, University of Pennsylvania (advisors: Chris Callison-Burch and Marianna Apidianaki), "Paraphrase-based Models of Lexical Semantics", May 2019. Current position: Senior Research Scientist at Netflix.
- Courtney Napoles, Johns Hopkins University (advisors: Chris Callison-Burch and Benjamin Van Durme), "Monolingual Sentence Rewriting as Machine Translation: Generation and Evaluation", June 2018. Current position: Engineering Director, NLP/ML/AI at Grammarly.
- Juri Ganitkevitch, Johns Hopkins University (advisor: Chris Callison-Burch), "Large-Scale Paraphrase Extraction and Applications", February 2018. Current position: Chief Scientist & Co-Founder at Espresso AI.
- Ellie Pavlick, University of Pennsylvania (advisor: Chris Callison-Burch), "Compositional Lexical Semantics in Natural Language Inference", July 2017. Current position: Assistant Professor at Brown University.
- Ann Irvine, Johns Hopkins University (advisor: Chris Callison-Burch), "Using Comparable Corpora to Augment Low Resource Statistical Machine Translation Models", July 2014. Current position: Chief Data Scientist & VP of Product Management at Resilience.
- Xuchen Yao, Johns Hopkins University (advisors: Benjamin Van Durme and Chris Callison-Burch), "Feature-Driven Question Answering with Natural Language Alignment", July 2014. Current position: Cofounder/CEO at Seasalt.ai and Vobil.com.
- Omar Zaidan, Johns Hopkins University (advisor: Chris Callison-Burch), "Crowdsourcing Annotation for Machine Learning in Natural Language Processing Tasks", April 2012. Current position: Senior Applied Scientist at Amazon.
Postdocs:
- Lara Martin, PhD from Georgia Tech, postdoc at University of Pennsylvania from 2021 through August 2023. Current position: Assistant Professor at University of Maryland, Baltimore County.
- Mohammad Sadegh Rasooli, PhD from Columbia University, postdoc at University of Pennsylvania from January 2020 through July 2021. Current position: Senior Applied Scientist at Microsoft.
- Derry Wijaya, PhD from Carnegie Mellon University, postdoc at University of Pennsylvania from 2016 through August 2018. Current position: Assistant Professor at Boston University.
- Anietie Andy, PhD from Howard University, postdoc at University of Pennsylvania from January 2017 through June 2018. Current position: Assistant Professor at Howard University.
- Wei Xu, PhD from New York University, postdoc at University of Pennsylvania from February 2014 through August 2016. Current position: Assistant Professor at Georgia Tech.
- Matt Post, PhD from University of Rochester, postdoc at Johns Hopkins University from September 2010 through June 2012. Current position: Researcher at Microsoft Translator.
- Alex Klementiev, PhD from UIUC, postdoc at Johns Hopkins University from November 2009 through July 2011. Current position: Principal Applied Scientist at Amazon.
I addition to helping my own students negotiate their faculty offers, I often help other PhD students negotiate their first faculty offers too. I have collected nearly 100 computer science faculty via this survey, and I share my spreadsheet of data with students to help them understand their offers, and often negotiate stronger offers.